- トップ >
- 使えるLabVIEWテクニック >
- バイナリデータを符号無し整数に変換する
バイナリデータを符号無し整数に変換する [ Binary To Unsigned Int ]
バイナリファイル等を扱う場合に、バイナリデータから整数を取り出す必要が出てきます。
複数バイトのサイズの整数を扱う場合に問題になるのがバイト順序(バイトオーダー)です。
バイトオーダーには、主に「ビッグエンディアン」と「リトルエンディアン」の二種類があります。
「ビッグエンディアン」は、データを大きい値に対応する上位バイトから並べます。この方式は、IBMの汎用計算機から、UNIX系のCPU、モトローラー系のCPUで採用されていました。そのため、「Motorola形式」と呼ぶ場合もあります。
「リトルエンディアン」は、データを小さい値に対応する下位バイトから並べます。この方式は、インテルのCPUで採用され普及したため、「インテル形式」と呼ぶ場合もあります。
ちなみに、LabVIEWの内部処理では、「ビッグエンディアン」が使われています。これは、 LabVIEWが元々AppleのMacintoshで開発されたソフトウェアであるり、当時のMacがMotorolaのCPUを使っていたためです。この二種類のバイト順序に対応してデータを変換するサブVIを作りました。
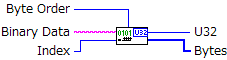
○使い方
サブVIは、16ビット、32ビット、64ビットの3種類がありますが、32ビットを例に説明します。
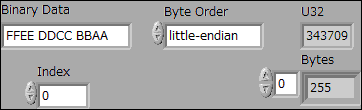
"Binary Data"に元になるバイナリデータを文字列形式で入力します。
"Byte Order"で、バイトオーダーを"big-endian"か"little-endian"を選択します。
"Index"には、データ読出し位置を入力します。
実行すると、
"U32"から、変換された値が出力されます。
"Bytes"からは、変換に使われた箇所のデータをバイト配列で出力します。
サンプルプログラム VI"BinaryToUInt.zip"(LabVIEW ver. 8.6版)
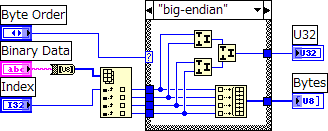
○仕組み
入力されたバイナリデータは、バイト配列に変換され、該当する箇所からデータを取り出します。
取り出したデータを、バイトオーダーに応じて適切に結合して数値に変換します。
テスト用プログラム VI"BinaryToUIntTest.vi"(LabVIEW ver. 8.6版)
テスト用VIも作りました。圧縮フォルダーに入っていますのでご利用ください。