- トップ >
- 使えるLabVIEWテクニック >
- Htmlのデータを取り出す
Htmlのデータを取り出す [ Html Section Data]
ウェブサイトを記述しているHtmlは、ヘッダ(head)や、ボディ(body)などのセクションと呼ばれる要素が集まって作られています。
Htmlの中から指定した要素のデータを取り出すサブVIを作りました。
○使い方
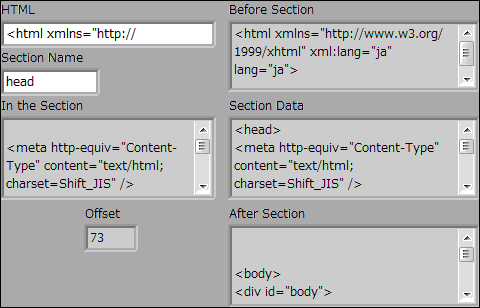
元になるHTMLを"Html"に入力し、取り出したいセクションのセクション名を"Section Name"に入力し実行します。
指定したセクションのデータを"Section Data"に出力します。
セクションの前にあったデータを"Before Section"に、後ろのデータを"After Section"に出力します。
セクションのデータから、セクションを切り分けるためのタグを取り除いたデータを"In the Section"に出力します。
Offserには、セクションがHtmlの何文字目から始まったかを示す数値が出力されます。
サンプルプログラム ZIP"HtmlSectionData.zip"(LabVIEW ver. 8.6版)
○仕組み
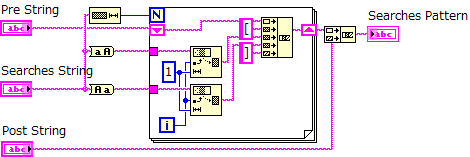
セクションに用いられるタグを探すために"パターンで一致"の関数を利用しています。
しかし、タグの表記では、大文字、小文字が混じって使われている事があるので、対応できるようにパターン文字を作る必要があります。
そこで、"AllCasePattern.vi"を利用してパターン文字を作成しています。
例えば、"html"と入力すると、"[Hh][Tt][Mm][Ll]"というパターンが出てきます。
このパターンで検索すると、"Html"や、"HTML"、"html"のどの状態でも探し出す事が出来ます。
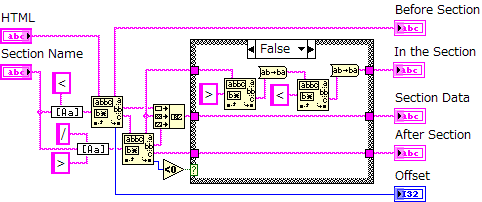
ケースストラクチャでは、閉じるタグ(</html>)が有る場合と、無い場合にわけて処理しています。
テスト用プログラム
テスト用VI "HttpAnaly.vi" も作りました。圧縮フォルダに入っていますのでご利用ください。